It feels weird to say that my development of this package started before I even realized that the final project for this class was developing an R package, but that’s exactly how it started.
- Package Context
- Development Notes (Research Team and AI Disclosure)
- openEvalR Package Specifics
- openEvalR Package Usage
- Package Link
Package Context
For a little bit of context — I currently work with Dr. Loni Hagen as her research assistant, which primarily consists of me running machine learning algorithms and statistical analyses to support her research. Our current project is looking at the Luigi Mangione case, and the frames of social media response and Sentiment. Its an ongoing project, and our first installment “Human and AI Alignment on Stance Detection: A Case Study of the United Healthcare CEO Assassination” will be presented at the FLAIRS-38 conference in May.
This project installment involved a significant amount of prompt engineering and model output evaluation using OpenAI’s API. We tested several models (GPT-4o Mini, GPT-o3 Mini, GPT 4.1, GPT 4.1 Mini) and evaluated them using several annotator agreeability metrics like Cohen’s Kappa, Qwet’s AC1, percent agreement against an established annotator Ground Truth.
These metrics are honestly fairly easy to calculate when your data is in the correct format. Packages like caret, irr, and irrCAC have accepted domain accepted functions that are trusted by the community for their accuracy and reliability, and I certainly was not going to try to recreate these functions but worse. The problem I ran into while evaluating our model results was the first sentence of this paragraph [“when your data is in the correct format“]
The thing about Open Ai’s model evaluation platform is that when you export results, you get them in a stupidly long and nested .jsonl format that was a pain to parse every time I needed to export our model results for evaluation. Honestly, I began dreading every time Dr. Hagen asked me to export our results because I knew I was about to have a 2-3 hour coding fight with these files just to parse it into an easily digestible format, such as a dataframe or a .csv.
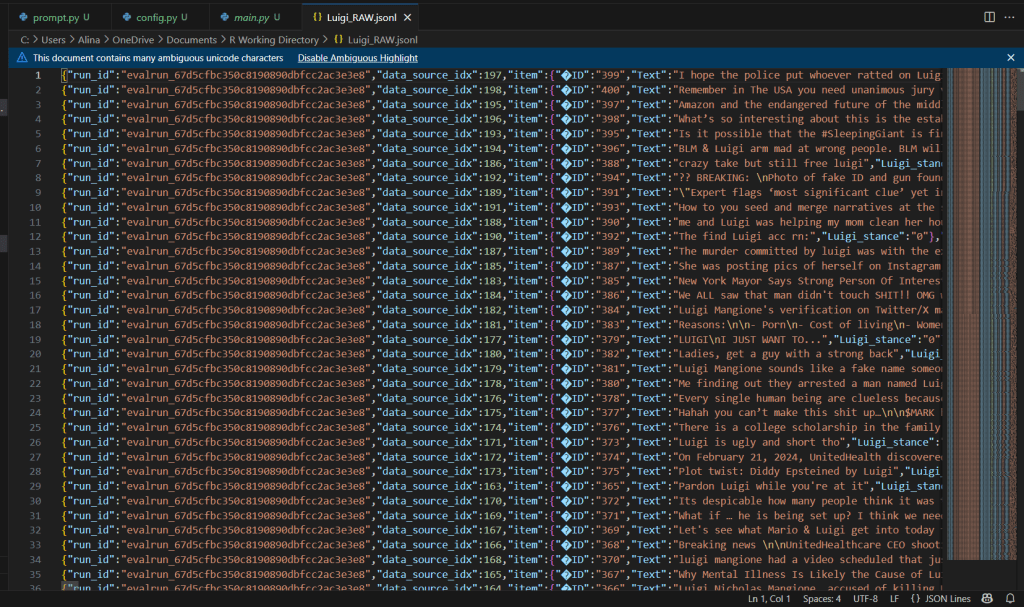
Here is a screenshot of what our raw results looked like and the files I fought
Now, are there R and Python packages that are designed for parsing json files? Yes, there are. But even with those resources, I would be writing and rewriting huge code blocks in order to manipulate these general libraries and packages into configuring my files over and over again.
As the weeks went on, I eventually did develop coding functions that I kept on file that slowly transformed my 2-3 hour coding fights into a much more manageable 5 minute RMarkdown set up. So, when I realized that the final project for LIS4370 was developing your own R Package, I realized that I had basically already done this in my official research position and decided to go the extra step and fully refine the workflow I developed into an official R package I could publish with our research results.
Development Notes (Research Team and AI Disclosure)
Before I get into development specifics I feel the need to clarify — While this package’s functions were developed in an official research position, this package and its functions were solely developed by me and were not written by the leading Dr.s and other assistants apart of the project.
Similarly, I will disclose that this project did make use of AI tools, such as OpenAI’s ChatGPT for the following:
Function Debugging:
When strange errors were encountered during function development, I used ChatGPT to figure out what they were telling me.
Specific Example: While I was writing my cmatrix() function, I encountered an error with one of my files, where my cmatrix function was working with all other raw jsonl results, but was failing with one. R gave me this error for that file:
> print(cmatrix(df3, "item.Agreed"))
Error in map():
ℹ In index: 1.
Caused by error in confusionMatrix.default():
! the data cannot have more levels than the reference
Backtrace:
1. base::print(cmatrix(df3, "item.Agreed"))
2. global cmatrix(df3, "item.Agreed")
3. purrr::map(...)
4. purrr:::map_("list", .x, .f, ..., .progress = .progress)
8. .f(.x[[i]], ...)
10. caret:::confusionMatrix.default(data[[model_col]], data[[groundtruth_col]])
11. base::stop("the data cannot have more levels than the reference")This confused me as my function worked with all other files, and only failed on one specifically. ChatGPT gave me this insight:

This insight helped me remember a very strange situation we encountered in our research that I hadn’t realized would impact the confusionMatrix() generation the way it did — our ground truth coding used 3 levels to denote three different stances for multiple topics (-1 = Negative, 0 = Neutral, 1 = Positive), however, for one of our topics, our ground truth annotation had one topic were no Positive stances were encountered in the sample set, so one of our Ground truth columns only had 2 levels. However, the model ended up denoting one of the sample texts as positive. Meaning, our ground truth column for that topic had two levels, and the model result had three levels — Exactly what this error reported.
This insight led me to add a this line of code to my cmatrix() function:
# This line specifically is very research specific
model_levels <- levels(factor(data[[model_col]]))
# Align both columns to use the same levels
prediction <- factor(data[[model_col]], levels = model_levels)
reference <- factor(data[[groundtruth]], levels = model_levels)(This was one of a couple situations that makes this package very tailored specifically to our research project, however when faced with a decision to make this package more generalizable or work best for our research, I made the decision to error on the side of our research)
Generate a synthetic testing file:
When I was finishing this package up, I had been regularly testing it with our research model results. I knew the package was working as I intended it, but I encountered a small situation when I realized I should probably provide a testing file people could use to test my package (given how specific this package it, its sort of hard to play with it without specific files).
Given the nature of our research, I was unsure if I would be allowed to share our raw results on this package’s page, partly due to privacy/GDPR concerns, and also the fact that we have not formally published this project’s GitHub.
Rather than risk it, I decided to ask Chatgpt to generate a synthetic file that mimicked the structure of our projects raw results with completely fake, topically neutral, dummy data.
Git and Version Control Errors:
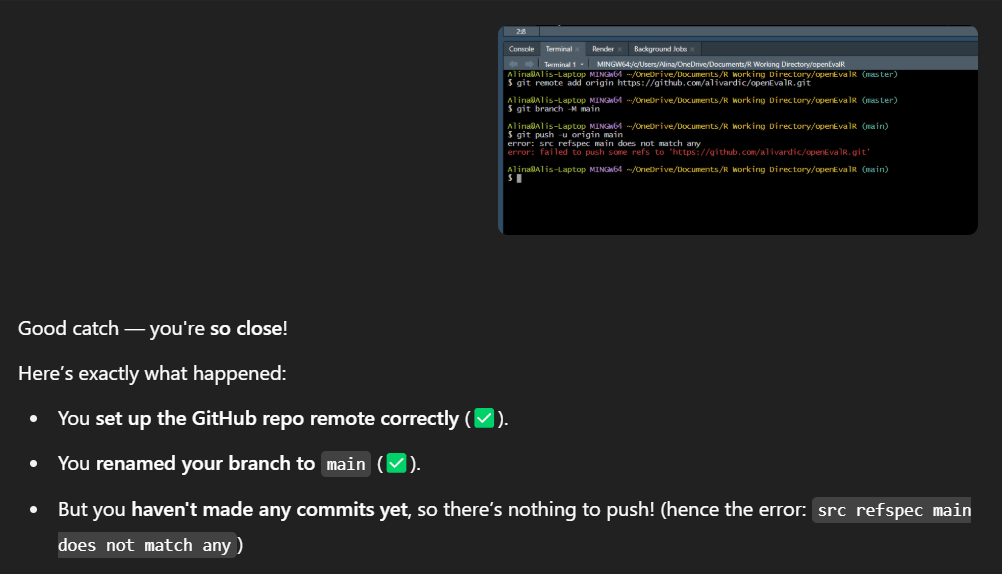
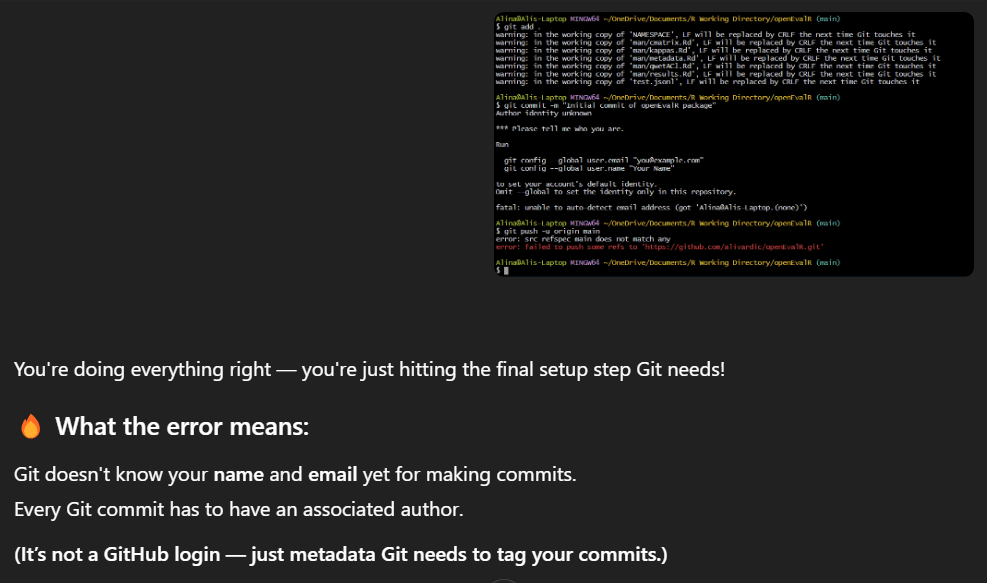
When my package was finished, and I was ready to publish, I wanted to publish my package using git commands in the R terminal (I think you can just upload your directory to GitHub, but I’m pretty sure it is best practice to use git commands, I’m not sure which one we were expected to do, but I decided I wanted to use git commands). I have never used the R terminal before, and I found using it very difficult. I encountered errors pretty much every step of the way, written in lingo I have never encountered before. Chatgpt was invaluable for decoding these git command errors and helping me figure out how to publish my package from the R terminal.
I encountered errors like not establishing my inital commit, not knitting my README.md, not setting my global name and email address, not logging in to GitHub correctly. It was honestly a little bit of an embarrassing fight but I am glad I took this approach and committed to uploading my package this way as you’ll never learn if you don’t jump in and figure it out.
Here are some screenshots of my rather embarrassing fight with the R Terminal and how I utilized Chatgpt to diagnosis and address git command errors:

With that out of the way — Lets talk a little bit more about my package:
#########################################
openEvalR Package Specifics
How many functions does openEvalR have?
- My package consists of 5 functions: results(), metadata(), kappas(), qwetAC1(), and cmatrix(). All of these functions were developed during my research analysis and were constantly used by me when evaluating model results, except for metadata(). metadata() was developed as a way to try and improve the generalizability of this package and expand its function list.
How many libraries does openEvalR use?
- 10. Many of these packages come from the fact that I used tidyverse programing style (My preferred coding style). 3 of them were called due to their industry accepted functions (irr’s kappa2(), caret’s confusionMatrix(), and irrCAC’s gwet.ac1.raw()). When I developed this package, I did not set out to reinvent the wheel for those functions and retained the utilization of other packages. My focus for this package was streamlining my research’s workflow.
What type of metadata does openEvalR hold?
- My package’s metadata includes its DESCRIPTION file (package title, version, author, dependencies, and description) , its NAMESPACE file (exported functions and imported functions from other packages, generated via devtools::document() ), and a README file (package development background and usage instructions).
What type of license does openEvalR maintain?
- The CC0 license (Creative Commons Zero 1.0 Universal)
What type of classes (S3 vs. S4) and methods can be found in openEvalR?
- Strictly S3 methodology
#########################################
openEvalR Package Usage
I added this development note to my README but I want to talk about it again here: Unfortunately, while this package was a lifesaver for me and my project, I struggle to see how other people might use this package.
The reason being, this package was designed to fit the model outputs of this projects .jsonl files, and its subsequent functions depend on the dataframe being formatted as such:
| data.idx | groundtruth | model_* | *_model_output | […] |
| […] | […] | […] | […] | […] |
When I began adapting my research workflow to function as a package, I was faced with the decision of if I should prioritize generalizability or my research project — for my own sake, I decided to prioritize my research project and my own peace of mind rather than the package’s generalizability.
That being said, I did make efforts to clearly document how this package expects to receive inputs so that if people did ever want to use it for their own model evaluation projects, this package could support them. I hope that this package might help people in the future, but at the very least, the functions developed for this package were invaluable for me and the statistical analysis I did for the stance detection research project, and I am very proud to be publishing this package alongside those research results.
Package Link
Here is a link to the GitHub repository I published for this package. I decided to publish a new one, rather than under my LIS4370 repository as I may be linking this package to the GitHub repository our research project eventually publishes.

Leave a comment